📝 I've written a detailed blog post about RAG introduction. Check out this post!
A modern application that combines document processing with AI capabilities, allowing users to upload files and have natural conversations with an AI assistant about their content through semantic search and vector embeddings.
| Category | Details |
|---|---|
| Frontend | React, TypeScript, Vite, TanStack Router/Query, Tailwind CSS, Shadcn UI |
| Backend | Hono, Drizzle ORM, PostgreSQL with pgvector |
| AI Integration | Mistral AI (embedding & mistral-large-latest), AI SDK |
| Type | Personal Project |
| Status | Private for now |
| Code | Private for now |
I'm a junior developer actively learning and building my skills. If you're interested in this project or would like to discuss potential job opportunities, please feel free to contact me directly.
Project Overview
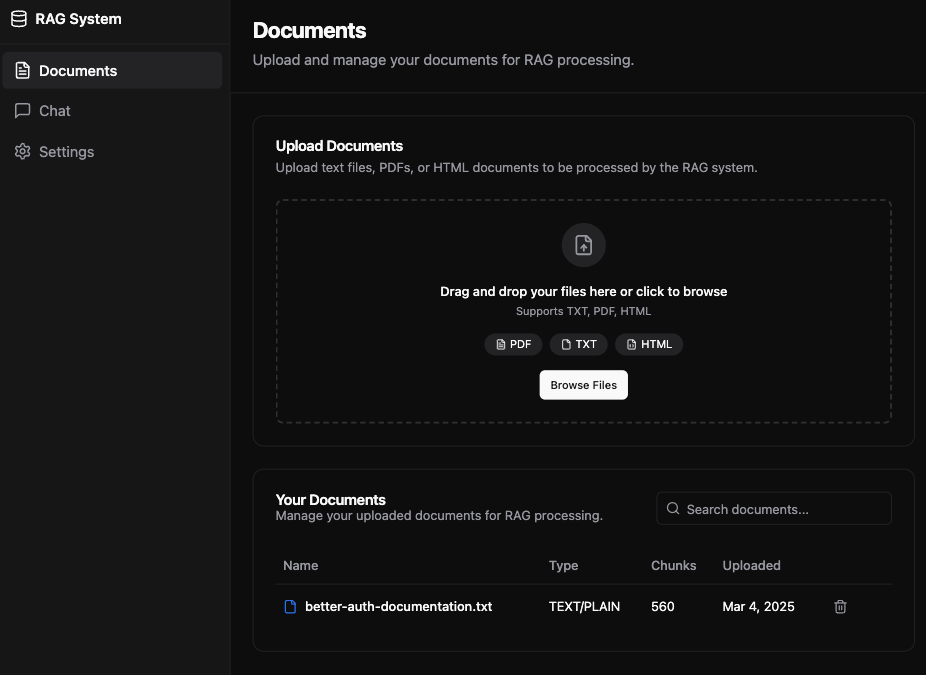
This project demonstrates the implementation of Retrieval Augmented Generation (RAG) in a practical application. It enables users to upload documents of various formats (PDF, HTML, TXT) and engage in context-aware conversations with an AI assistant that can reference specific information from these documents.
Technical Implementation
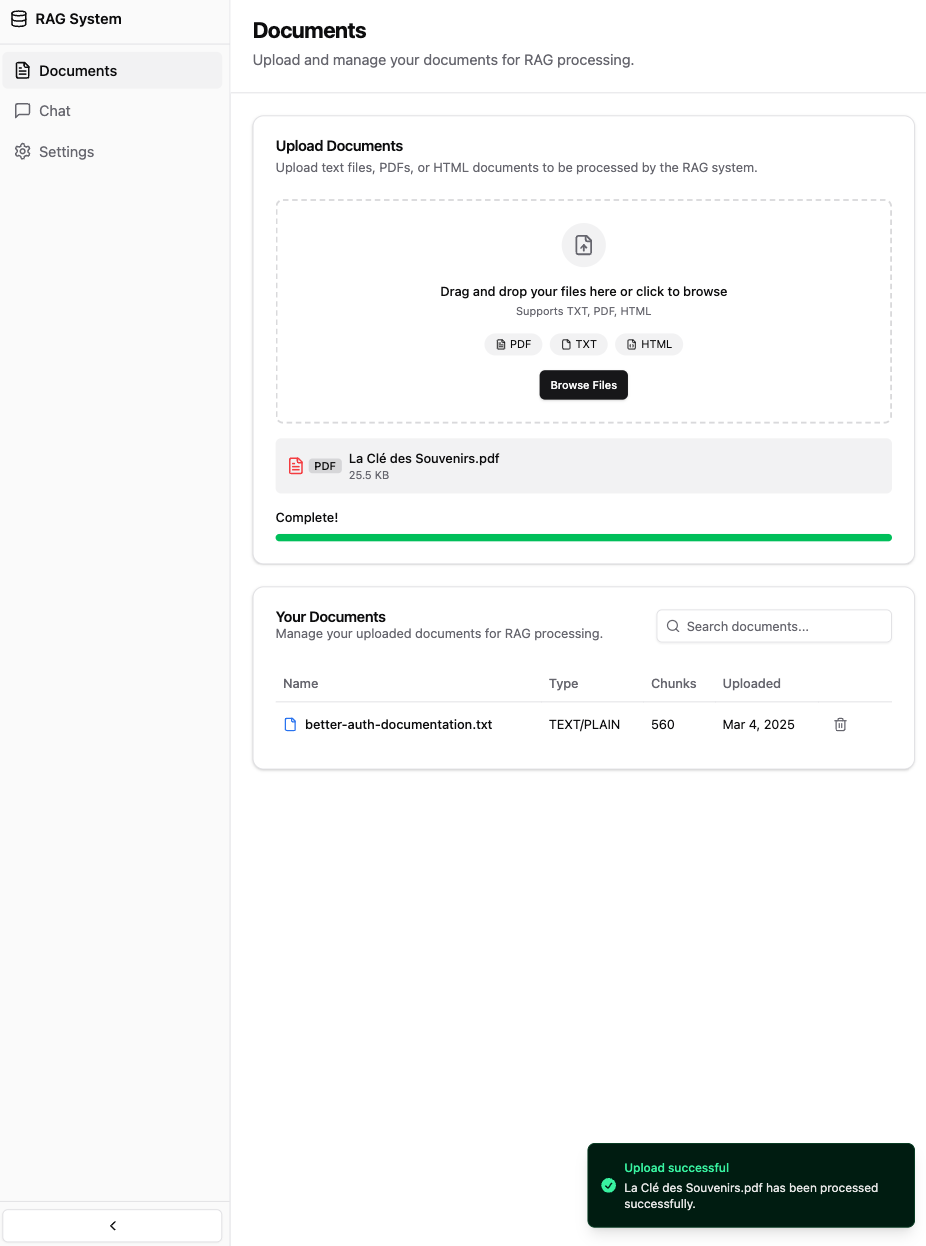
The application architecture consists of a modern React frontend built with Vite and TypeScript, with a lightweight Hono-based Node.js backend. Document processing happens in multiple stages: parsing, chunking, generating embeddings using Mistral's mistral-embed model, and storing these vector representations in PostgreSQL using the pgvector extension. When users ask questions, the application retrieves relevant document chunks and uses Mistral's mistral-large-latest model to generate informative responses.
Key Features
| Feature | Implementation |
|---|---|
| Document Processing | Multi-format support with automated chunking and embedding |
| Vector Search | Semantic similarity search using pgvector |
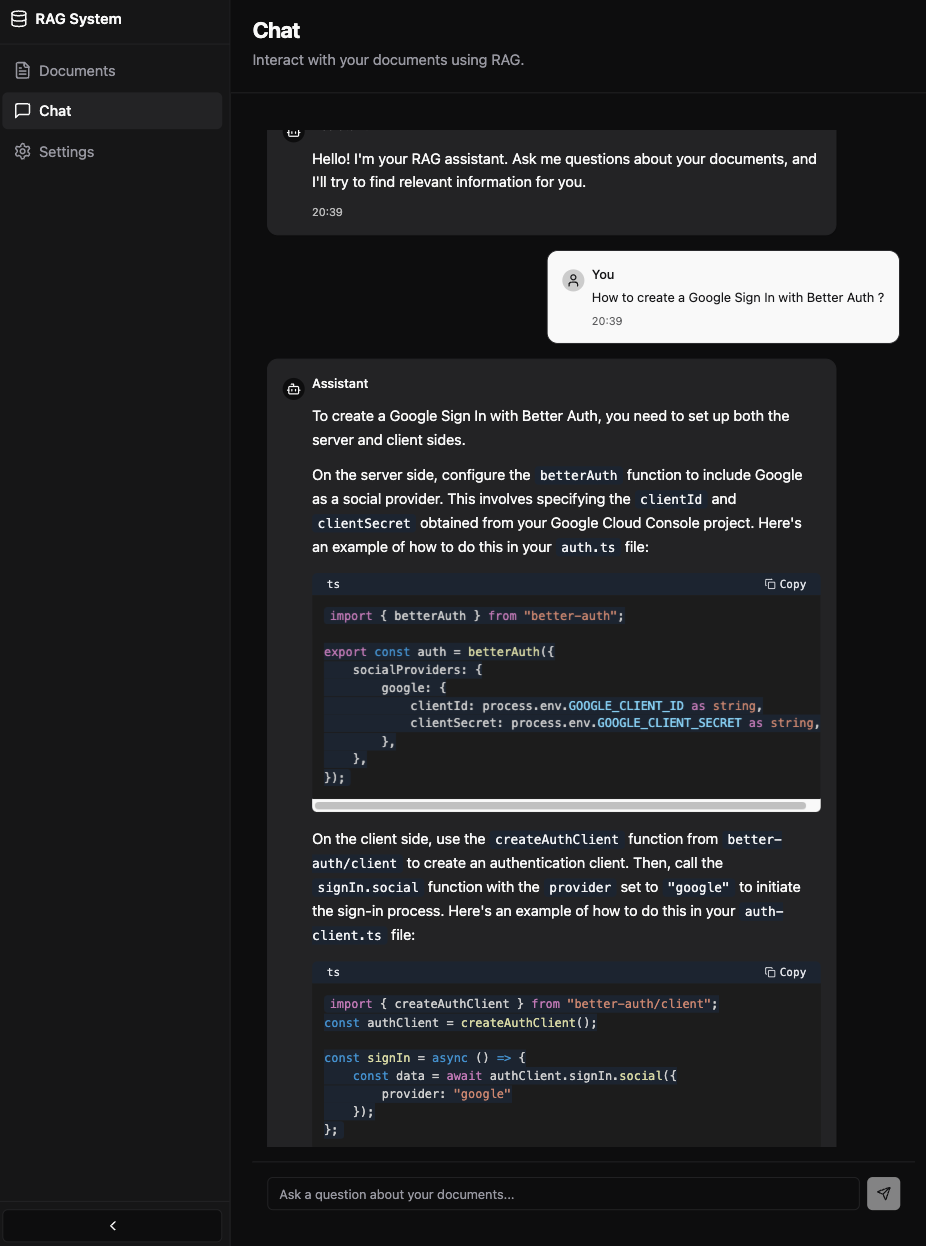
| AI Chat Interface | Stream-based responses with Mistral Large model |
| Document Management | Upload and delete documents |
| Theme Support | Dark/light mode |
Development Challenges
Building this application presented several technical hurdles that required thoughtful solutions:
| Challenge | Solution |
|---|---|
| Different Format Types | Implemented specialized handlers for PDF, HTML, and TXT formats |
| Chunking Strategy | Used Langchain text splitter with optimal overlap for context preservation |
| Vector Database Integration | How to add pgvector to a PostgreSQL database |
| Streaming Responses | AI SDK integration with frontend and backend |
Architecture Overview
The RAG pipeline follows these key steps:
- Document upload and parsing to extract raw text
- Text chunking
- Vector embedding generation using Mistral embedding models
- Storage in PostgreSQL with pgvector for efficient similarity search
- Query processing that combines retrieved context with AI generation using Mistral's large language model
Learning Outcomes
This project provided extensive learning opportunities in:
- Vector database implementation
- LLM integration for document understanding
- Streaming AI responses
- Document processing pipelines
- Semantic search implementation
The project demonstrates how Retrieval Augmented Generation can significantly enhance applications by grounding responses in specific document contexts and providing more accurate information retrieval compared to traditional approaches.