Table of Contents
⚠️ Remember: This post is an introduction to RAG concepts as I understand them. I'm sharing my learning process—I can make mistakes. Philosophy about the blog.
💼 Open to work opportunities in web development. Let's connect!
🔗 Want to see how this project was built? Check out to the project section!
Introduction
Retrieval-Augmented Generation (RAG) has become a fundamental approach in modern AI applications, enabling models to provide more accurate, up-to-date, and contextually relevant responses. Unlike traditional language models that rely solely on their training data, RAG systems can retrieve and incorporate external knowledge when generating responses.
In this introduction, we'll explore the essential components that make RAG work effectively: chunking and embeddings. Understanding these concepts is crucial for anyone looking to implement their own RAG system or optimize an existing one.
Note: This article assumes basic familiarity with language models but aims to make these concepts accessible to technical and semi-technical readers alike.
RAG Fundamentals
What is RAG?
Retrieval-Augmented Generation (RAG) is a hybrid approach that combines the strengths of retrieval-based systems with generative AI. The process involves:
- Retrieval: Fetching relevant documents or data from a knowledge base
- Augmentation: Passing the retrieved data to a generative model
- Generation: Producing a response based on both the retrieved context and the model's capabilities
This approach addresses a key limitation of traditional language models: their inability to access specific information beyond their training data.
Key Components
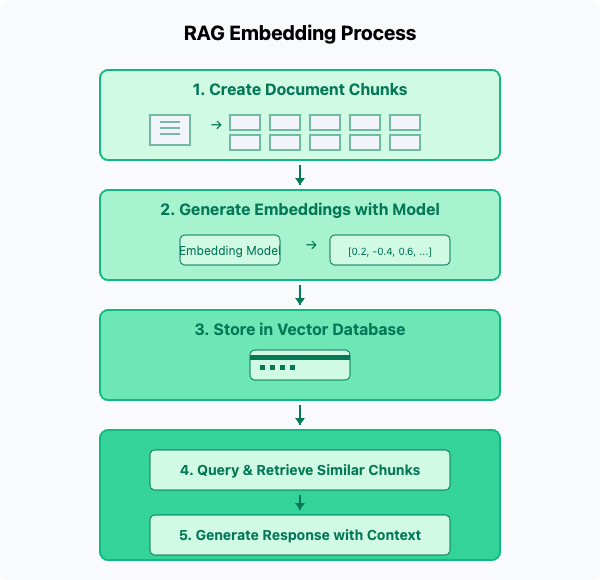
A typical RAG pipeline consists of several core elements:
- Document Processing: Converting raw documents into a searchable format
- Chunking: Breaking documents into smaller, manageable pieces
- Embedding Generation: Creating numerical representations of text chunks
- Vector Storage: Efficiently storing and indexing these embeddings
- Retrieval Mechanism: Finding the most relevant information for a query
- Generation: Using retrieved context to produce accurate responses
While each component is important, we'll focus specifically on chunking and embeddings—two crucial elements that significantly impact RAG performance.
Chunking
Chunking is the process of splitting long texts into smaller, more manageable pieces. This might seem like a simple preprocessing step, but it profoundly impacts the effectiveness of your entire RAG system.
Why Chunking Matters
There are several compelling reasons to implement chunking in your RAG pipeline:
-
Improved Retrieval Precision: Smaller chunks allow for more precise matching of relevant content to specific queries.
-
Working Within Model Limits: Most embedding models have token limits. Chunking ensures your content fits within these constraints.
-
Context Window Optimization: LLMs have limited context windows. Smaller, more relevant chunks make better use of this limited space.
-
Better User Experience: Returning concise, relevant chunks is more useful than overwhelming a user with entire documents.
Without effective chunking, your RAG system might struggle with precision and efficiency, especially as your knowledge base grows.
Chunking Strategies
Several approaches can be used for chunking, each with its own strengths:
-
Fixed-Length Chunking: Splitting by character or word count (e.g., every 500 characters or 200 words)
- Pros: Simple to implement
- Cons: May break semantic units
-
Semantic Boundary Chunking: Splitting by sentences, paragraphs, or sections
- Pros: Preserves natural language boundaries
- Cons: More complex to implement
-
Token-Based Chunking: Using a tokenizer to split by token count
- Pros: Directly addresses model constraints
- Cons: Requires understanding of tokenization
-
Hybrid Approaches: Combining methods (e.g., splitting by paragraphs but ensuring no chunk exceeds a token limit)
- Pros: Balanced approach
- Cons: Increased implementation complexity
| Chunking Strategy | Best Use Case |
|---|---|
| Fixed-Length | Simple implementations, homogeneous content |
| Semantic | Content with clear structure (articles, documentation) |
| Token-Based | When working with specific LLM API constraints |
| Hybrid | Production systems requiring balance of precision and performance |
Real-world Example
Let's consider a practical example to illustrate chunking in action:
Imagine you have a 1,000-word article about climate change. Using a semantic chunking approach, you might divide it into:
Chunk 1: Introduction and problem statement [180 words]
Chunk 2: Historical climate data [220 words]
Chunk 3: Current impacts [250 words]
Chunk 4: Future projections [200 words]
Chunk 5: Potential solutions [150 words]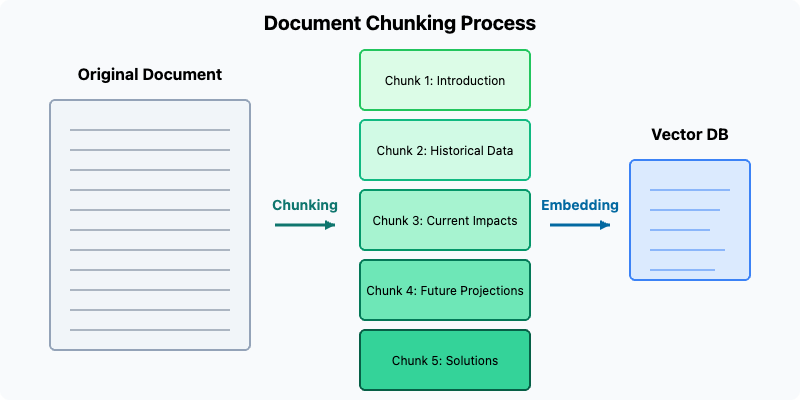
This approach preserves the logical structure of the article while creating manageable units for embedding and retrieval.
Embeddings
Embeddings are the numerical representation of text that capture semantic meaning in a way that computers can process. They form the foundation of how RAG systems understand and retrieve information.
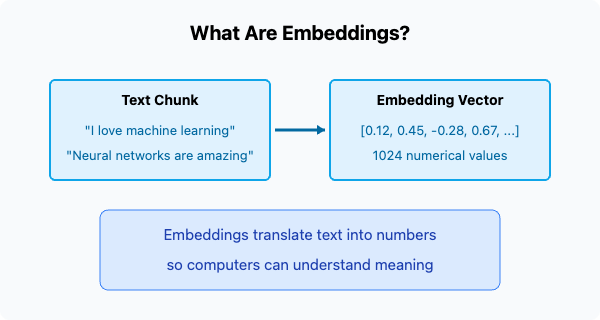
What Are Embeddings?
An embedding is essentially a list of numbers (a vector) that represents the meaning of a piece of text. Modern embedding models convert words, phrases, or entire chunks of text into high-dimensional vectors that capture semantic relationships.
For example, in a good embedding space:
- Similar concepts have similar vector representations
- Different meanings of the same word are distinguished by context
- Relationships between concepts are preserved (e.g., "king" - "man" + "woman" = "queen")
Understanding Embedding Dimension
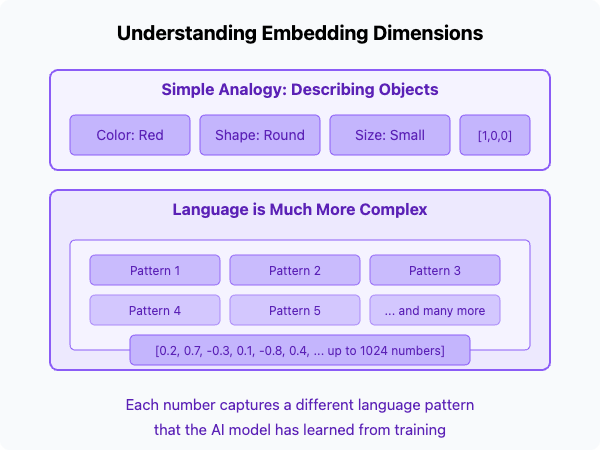
Embedding models like those from Mistral, OpenAI, or Anthropic typically produce vectors with hundreds or thousands of dimensions. For instance, Mistral's embedding model creates 1024-dimensional vectors.
This might sound abstract, so let's break it down with a simpler analogy:
Imagine describing a person using just three numbers:
- Height: 1.75m
- Weight: 70kg
- Age: 25 years
That's a 3-dimensional vector describing a person.
Text embeddings work similarly but use many more dimensions (e.g., 1024) to capture nuanced aspects like:
- Topic and subject matter
- Writing style and tone
- Entity relationships
- Semantic meaning
- And many other language features
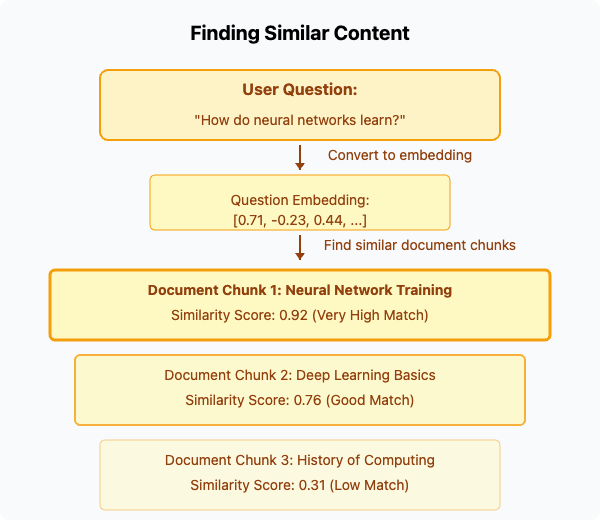
Similarity Search
The power of embeddings comes from how they enable similarity search—finding related content by measuring the "distance" between vectors.
When a user asks a question, the RAG system:
- Creates an embedding of the question
- Compares it to the embeddings of all chunks in the database
- Retrieves the chunks whose embeddings are closest to the question's embedding
This vector similarity search is what allows RAG systems to find relevant information without relying on exact keyword matching.
// Example (conceptual)
"I love cats" → [0.1, 0.2, 0.3, ..., 0.9] // 1024 numbers
"I like cats" → [0.11, 0.19, 0.31, ..., 0.89] // similar numbers
"I hate math" → [-0.5, 0.8, -0.2, ..., 0.1] // very different numbers
Understanding Tokens
When implementing RAG, you'll frequently encounter the concept of "tokens," which play a crucial role in both chunking and embedding processes.
Token Basics
Tokens are the basic units that language models process. They don't always correspond directly to words:
- "hello" → 1 token
- "understanding" → 2 tokens ("under" + "standing")
- "I love cats" → 3 tokens
- "🌟" (emoji) → might be 1-2 tokens
The exact tokenization depends on the specific model and tokenizer being used.
Tokens in RAG Pipelines
Understanding tokens matters for several reasons in RAG systems:
-
API Limits: Most embedding and LLM APIs have token limits per request
- Example: If a limit is 8,192 tokens and your text is 10,000 tokens, you'll need to chunk it
-
Cost Considerations: Many APIs charge per token processed
- More tokens = higher costs
-
Chunking Strategy: Token-aware chunking ensures you stay within API constraints
- Character-based chunking might create chunks that exceed token limits
| When to Care About Tokens | Recommendation |
|---|---|
| Using embedding APIs with strict limits | Implement token-counting in your chunking strategy |
| Cost-sensitive applications | Monitor token usage and optimize chunk sizes |
| Simple prototyping | Start with character-based chunking; add token awareness if needed |
| High-volume production systems | Implement token-based chunking with overlap |
Implementation Considerations
When implementing chunking and embeddings in your RAG system, consider these practical tips:
-
Chunk Size Trade-offs:
- Too large: Less precise retrieval, may hit token limits
- Too small: More storage overhead, might lose context, higher API costs
-
Chunk Overlap:
- Including some overlap between chunks (e.g., 10-20%) helps preserve context
- Especially important for semantic chunking where concepts might span chunk boundaries
-
Storage Architecture:
- Store not just embeddings but also:
- Original document reference
- Chunk metadata (position, source, etc.)
- Raw text for context window insertion
- Store not just embeddings but also:
-
Database Selection:
- Vector databases (like pgvector) optimize similarity search
- Consider hybrid approaches that combine vector and keyword search
-
Embedding Model Selection:
- Domain-specific vs. general-purpose
- Dimensionality (higher isn't always better)
- Throughput vs. quality trade-offs
Conclusion
Chunking and embeddings form the foundation of effective RAG systems. By properly implementing these components, you can significantly improve the relevance, accuracy, and efficiency of your AI applications.
Remember:
- Chunking is about breaking content into the right-sized pieces for your specific use case
- Embeddings transform text into a format that machines can understand and compare
- The right balance of chunk size, overlap, and embedding quality can dramatically improve retrieval performance
Whether you're building a custom knowledge base, enhancing customer support, or developing research tools, mastering these concepts will help you create more effective systems.